
Open your phone right now and think about everything happening behind the scenes. Every search you make, every video you watch, every online purchase, every swipe, tap, or scroll generates data. And not just a little. We’re talking about over 328 million terabytes of data created every single day worldwide. Companies are drowning in information, and the pace isn’t slowing down. This explosion has created a huge challenge: How do we store all this data, process it fast enough, and make sense of it in a way that actually helps businesses? That’s where the world often gets a bit confusing. People sometimes mix up two very different things: Big Data and Apache Hadoop. One refers to the problem, the flood of information. The other is one of the solutions that helps manage it.
In this blog, we will clear up the confusion once and for all. We will break down what Big Data really means, what Hadoop actually does, and how they differ. Then we will dive into real-world examples, practical use cases, and how both work together in modern data-driven companies. By the end, you will have a clear picture of where each one fits and why both matter in today’s data-heavy world.
What is Big Data?
Big Data is not just a buzzword anymore. It’s the backbone of how modern organizations operate. At its core, Big Data refers to extremely large and complex datasets that traditional databases and tools simply can’t handle. We’re talking about data so massive and so fast-moving that old-school systems break under the pressure. Every minute, the world generates:
- 6 million Google searches
- 65,000 Instagram photos
- 1 million hours of Netflix content streamed
- 241 million emails sent
This is Big Data in action, endless streams of information coming from everywhere: apps, sensors, transactions, social media, machines, and customer interactions. Because of this overwhelming scale and complexity, new ways of storing, processing, and analysing data became necessary. Experts typically describe Big Data using the 3Vs framework, though many industries have extended this into 5Vs or even 7Vs to capture its full nature. These characteristics help explain why Big Data is so powerful and so challenging.
Key Characteristics of Big Data
1. Volume: This is the most obvious part. Big Data involves massive quantities of information, often running into terabytes, petabytes, and sometimes exabytes. For example, YouTube users upload 500+ hours of video every minute, and by 2030, global data generation is expected to reach over 600 zettabytes. Traditional databases simply cannot scale to this level.
2. Velocity: Data isn’t just large. It’s fast. Velocity refers to the speed at which data is generated, streamed, and processed. Think of stock market transactions, real-time fraud alerts, or live GPS data from thousands of vehicles. Systems need to capture and react to information instantly.
3. Variety: Data no longer comes in neat, structured tables. It appears in all shapes and forms:
- Structured: databases, financial records
- Semi-structured: JSON, XML, logs
- Unstructured: images, videos, emails, audio, social media posts
- This mix makes analysis more powerful but far more complex.
4. Veracity: Not all data is clean or reliable. Veracity deals with accuracy, trustworthiness, and noise in data. For example, social media data is full of opinions, sarcasm, and inconsistencies — but businesses still need to make sense of it.
5. Value: Data alone means nothing unless you can extract value. Companies use Big Data to find patterns, improve decisions, and uncover opportunities that weren’t visible before.
6. Variability: Data can be unpredictable. For instance, user activity spikes during festivals, sales, or viral events. Systems must adapt to sudden changes without failing.
Why Big Data Matters?
Big Data is powerful because it turns raw information into real impact. When organizations know how to use it well, it transforms how they operate, compete, and grow.
- 1. Unlocking Deeper Business Insights: Companies can analyze years of historical data combined with real-time trends to uncover customer behavior, market patterns, and operational bottlenecks. This helps leaders make smarter decisions with confidence.
- 2. Predictive Analytics: From forecasting product demand to predicting machine failures, Big Data fuels models that can forecast what’s likely to happen next. Retail giants like Walmart use it to predict buying patterns before customers even walk into the store.
- 3. Improved Customer Experience: Big Data helps companies personalize everything — product recommendations, service responses, app experiences, even pricing. That’s why platforms like Netflix know exactly what you’ll want to watch next.
- 4. Fraud Detection and Risk Management: Banks and fintech companies rely on Big Data systems that analyze thousands of transactions per second to detect suspicious behavior. These systems catch anomalies long before a human could.
- 5. Automation and Optimization: Manufacturing plants use sensor data to automate processes, cut downtime, and improve safety. Logistics companies use Big Data to optimize delivery routes in real time. Even hospitals use it to automate patient monitoring.

What Is Apache Hadoop?
Imagine trying to store and process billions of records on a single computer. It would crash, slow down, or simply give up. That’s exactly the problem companies faced in the early 2000s, when data volumes exploded faster than hardware could keep up. Apache Hadoop stepped in as a game-changer. Hadoop is an open-source framework designed to store and process massive datasets across clusters of ordinary, low-cost computers. Instead of relying on a single powerful machine, Hadoop breaks the workload into smaller pieces and distributes them across multiple machines working together. This approach makes it possible to handle data at Google, Facebook, and Amazon scale — even without owning supercomputers. It became so successful that by 2015, over half of Fortune 500 companies had adopted Hadoop in some part of their data strategy. Today, it remains one of the foundational technologies in the Big Data world.
Core Components
Hadoop isn’t one single tool. It’s a collection of components that work together to store, manage, and process huge datasets.
1. HDFS (Hadoop Distributed File System) — Distributed Storage: HDFS stores data across multiple machines in a cluster. Instead of saving a file in one place, it splits it into blocks and spreads those blocks across different nodes. Why this matters:
- You can store petabytes of data without special hardware.
- If one machine fails, your data is still safe because HDFS automatically keeps multiple copies (replicas).
- It provides high-throughput access perfect for large-scale analytics.
2. MapReduce Distributed Processing: MapReduce is the engine that processes data in parallel. It breaks a task into hundreds or thousands of tiny sub-tasks, distributes them across the cluster, and then combines the results. Google originally created this model, and Hadoop adopted it to process huge workloads efficiently. It handles:
- Sorting
- Filtering
- Aggregating
- Running analytical jobs on massive data
3. YARN Resource Management: Think of YARN as Hadoop’s traffic controller. YARN makes sure your cluster stays organized and performs at its best, even with hundreds of jobs running simultaneously. It decides:
- Which job gets how much memory
- How CPU resources are allocated
- How tasks are scheduled across the cluster
4. Hadoop Common — Shared Utilities: This includes all the essential tools, Java libraries, and utilities that other Hadoop components depend on. It acts like the glue that holds everything together.
Hadoop Ecosystem Tools (Brief Overview)
Over time, Hadoop grew into a massive ecosystem. These tools sit on top of Hadoop to make data processing easier, faster, and more intelligent.
- Hive: A data warehousing tool that lets you write SQL-like queries (HiveQL) instead of writing MapReduce code. Great for analysts who prefer SQL over coding.
- Pig: A scripting platform (Pig Latin) used for transforming and analysing large datasets. More flexible than SQL and great for complex ETL jobs.
- HBase: A NoSQL database that stores massive tables with millions of rows and columns. Useful when you need quick read/write access at scale.
- Sqoop: Used to transfer data between Hadoop and traditional databases like MySQL, Oracle, or SQL Server.
- Flume: A tool for ingesting huge amounts of streaming data, especially logs. Perfect for real-time analytics and monitoring.
- Spark: Although not originally part of Hadoop, Spark integrates tightly with HDFS. It’s much faster than MapReduce because it processes data in-memory. Companies often pair Hadoop storage (HDFS) with Spark processing for high performance analytics, machine learning, and streaming.
What Hadoop Solves?
Apache Hadoop became famous because it solved some of the biggest challenges businesses faced when data started growing uncontrollably.
- Scalability Issues: Instead of buying expensive machines, Hadoop lets you add more cheap machines to scale horizontally. Need more capacity? Add more nodes.
- Cost-Effective Storage: Hadoop runs on commodity hardware, which means you don’t need supercomputers or high-end servers. A traditional data warehouse can be extremely expensive — Hadoop gives you the same capability at a fraction of the cost.
- Fault Tolerance: If one machine dies, your data doesn’t. HDFS creates copies of data blocks on different nodes, so the system keeps running with zero interruption.
- Handling Traditional System Bottlenecks: Conventional databases struggle with:
- Large files
- Unstructured data
- Real-time workloads
- High concurrency
Hadoop breaks through these bottlenecks by distributing both data and computation across many machines.

Big Data vs Apache Hadoop: Core Differences
Before diving into the differences, it’s important to understand one thing clearly:
Big Data is a concept. Hadoop is a framework. One represents the challenge. The other is one of the most successful responses to that challenge.
But the confusion happens because both appear in the same conversations and are deeply linked. This section clears that up with a full breakdown of how they differ across meaning, purpose, technology, structure, processing models, use cases, and more.
Big Data refers to enormously large, varied, and fast-moving datasets that cannot be processed using traditional data management tools like RDBMS, Excel, or single-server systems. Whereas Apache Hadoop refers to an open-source ecosystem designed to store, distribute, and process Big Data across clusters of low-cost machines. To put this simply:
- Big Data = “The problem (data overload).”
- Hadoop = “One of the solutions (a framework to handle that overload).”
Detailed Comparison Table
Below is a deeply detailed table that covers both conceptual and technical differences:
| Parameter | Big Data | Apache Hadoop |
|---|---|---|
| Meaning | Refers to extremely large, complex datasets. | A distributed framework that stores and processes Big Data. |
| Nature | A challenge or phenomenon. | A technological solution. |
| Scope | Very broad: includes data types, patterns, analytics, governance, tools, AI models. | Narrower: focuses on distributed storage, processing, and resource management. |
| Core Elements | Volume, Velocity, Variety (with extensions like Veracity, Value). | HDFS, MapReduce, YARN, Hadoop Common (plus ecosystem tools). |
| Purpose | To describe data that cannot be handled traditionally. | To solve scalability, cost, and processing limitations. |
| Type of Term | Conceptual, descriptive. | Practical, implementable technology. |
| Data Size It Deals With | Terabytes to zettabytes. | Same range, but within cluster limits. |
| Data Handling | Doesn’t handle data by itself. It’s just the “type” of data. | Actually handles storage, processing, movement, fault-tolerance. |
| Data Structure | Includes structured, semi-structured, unstructured. | Optimized for handling all three types, especially unstructured. |
| Architecture | No fixed architecture. | Cluster-based distributed architecture. |
| Processing Methodologies | Can use Hadoop, Spark, Flink, Presto, NoSQL, ML platforms. | Primarily MapReduce (batch processing), can integrate with Spark for faster processing. |
| Technologies Involved | Spark, Hadoop, Kafka, Cassandra, MongoDB, Hive, NiFi, Flink, and many more. | Only those within the Hadoop ecosystem. |
| Key Use Cases | Predictive analytics, customer segmentation, IoT insights, fraud detection, large-scale BI. | Distributed storage, ETL pipelines, log analysis, batch analytics, fault-tolerant processing. |
| Cost Factor | Depends on tools used—can be expensive or cost-effective. | Known for being cost-efficient due to commodity hardware. |
| Vendor/Platform Dependence | Not tied to any vendor. | Fully open-source; extended by Cloudera, Hortonworks, MapR. |
| Accessibility | Anyone can produce Big Data. | Requires proper setup, clusters, and technical skill to use. |
| Relationship With Hadoop | The problem Hadoop is built to solve. | The technology built to process Big Data. |
Explanation of Key Differences
1. Concept vs. Solution: Big Data describes the situation companies face today — massive, messy, high-speed data. Hadoop provides a framework to tackle that situation. It’s like saying, Big Data is like pollution, and pollution Hadoop is the Air purifiers. One exists naturally. The other is created to solve it.
2. Scope and Coverage: Big Data has a broad scope. It covers:
- Data sources
- Data formats
- Analytics
- Data engineering
- Machine learning
- Governance
- Storage
- Infrastructure
- Privacy and compliance
Hadoop’s scope is narrower and more technical:
- Distributed file system (HDFS)
- Batch processing (MapReduce)
- Resource management (YARN)
- Ecosystem tools (Hive, Pig, HBase, Spark, Flume)
Big Data talks about the world of data challenges. Hadoop talks about how to store and compute that data.
3. Data Processing Approach: Big Data doesn’t prescribe any processing technique. It can be processed using:
- Hadoop MapReduce (batch)
- Spark (in-memory, very fast)
- Flink (real-time streaming)
- Storm (real-time events)
- Presto (interactive SQL)
- Snowflake or BigQuery (cloud analytics)
Hadoop, in its native form, relies mainly on:
- MapReduce for distributed batch processing
- Works closely with Spark for faster processing
- Integrates with multiple ecosystem tools for querying, ingestion, and analytics
4. Real-Time vs. Batch: Big Data does not define if data should be real-time or batch. It covers both. On the other hand, hadoop (specifically MapReduce) is built primarily for batch processing. Though ecosystem tools like Spark Streaming or Kafka integrations help Hadoop handle near real-time cases, native Hadoop itself is not real-time.
5. Cost and Infrastructure: Big Data solutions vary widely. Some require expensive servers (like on-prem systems). Some are cheap (cloud pay-as-you-go models). Hadoop was designed to be cheap, scalable, and reliable, using:
- Commodity hardware
- Open-source software
- Horizontal scaling
This is why companies like Facebook and LinkedIn adopted Hadoop early when their data grew beyond traditional databases.
6. Data Types: Big Data includes all types of data:
- Structured (tables, SQL)
- Semi-structured (JSON, XML, logs)
- Unstructured (images, videos, audio, emails, sensor data)
Hadoop was built specifically to handle semi-structured and unstructured data, something traditional RDBMS systems struggle with.
7. Flexibility and Vendor Independence: Big Data tools differ from vendor to vendor. Cloud platforms like AWS, Azure, and GCP have their own implementations. Hadoop remains:
- Open-source
- Highly customizable
- Supported by global communities
- Extended through distributions like Cloudera and Hortonworks
This makes Hadoop extremely flexible.
8. Relationship Between the Two
In modern enterprises:
- Big Data → represents the challenge
- Hadoop → is one of the most widely-used tools to address that challenge
They coexist in almost every organization’s data strategy.
To understand better, real-world example Let’s say a telecom company collects:
- 50 TB of call records every day
- 20 TB of network logs
- Billions of SMS and browsing data points
That’s Big Data.
To manage it, they use:
- HDFS to store everything
- YARN to manage resources
- MapReduce/Spark to process daily analytics workloads
- Hive to query the processed results
That’s Hadoop solving the Big Data challenge. Simply saying, Big Data is the reason the modern data industry exists. Hadoop is one of the strongest and most reliable tools built to handle that data. You can think of them as two sides of the same coin different roles, tightly connected, but never interchangeable.
How Big Data and Hadoop Work Together?
Think of Big Data as a roaring river of information and Hadoop as a smart dam-and-turbine system: it captures the flow, stores it safely, and converts that energy into useful power. This section walks through the concrete ways they interact: architecture, workflows, integration points, real-world patterns, performance considerations, and operational best practices.
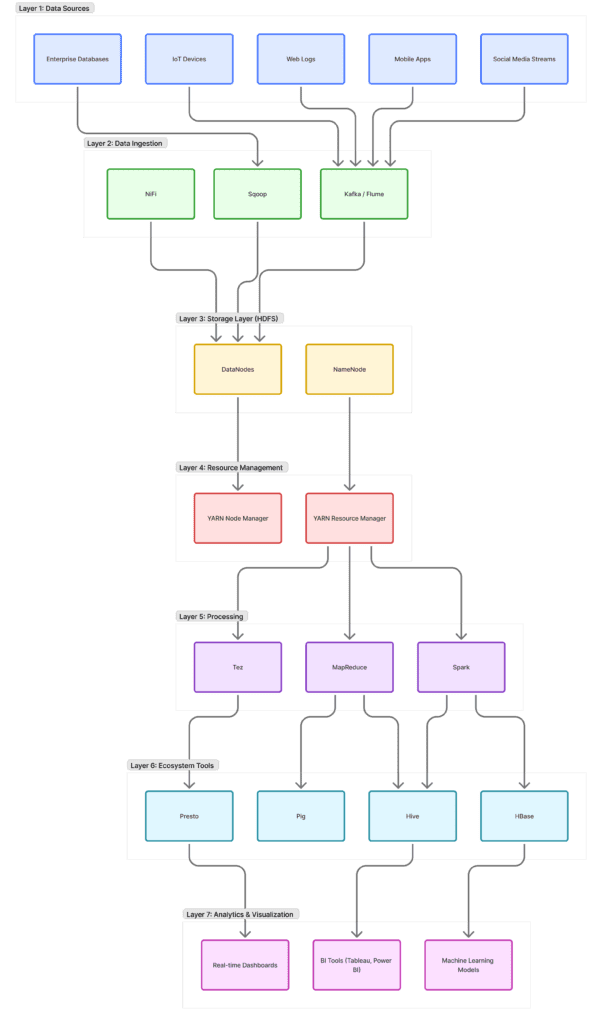
A. High-Level architecture — The Layers
A typical Big Data + Hadoop architecture looks like layered plumbing. Each layer has a clear responsibility:
- Ingestion / Collection — get data into the system
- Storage — durable, distributed storage (HDFS / object stores)
- Processing — batch and stream compute (MapReduce, Spark, YARN)
- Metadata & Governance — catalog, lineage, security, policies
- Serving & Analytics — query engines, dashboards, ML model serving
- Archival / Cold Storage — cheaper long-term storage
Simple ASCII flow:
Data Sources --> Ingest (Flume, Kafka, Sqoop, NiFi) --> Storage (HDFS / HDFS + HBase / Cloud Object Store) --> Processing (MapReduce / Spark / Tez / YARN) --> Serving (Hive, Presto, HBase, Druid) --> BI / ML / Applications --> Archive (tape / cloud glacier / cold HDFS)
B. Step-by-Step Workflow
1) Data ingestion
- Sources: web/mobile apps, logs, IoT sensors, RDBMS, social feeds, clickstreams.
- Tools: Flume, Sqoop, Kafka, NiFi, custom agents.
- What happens: data is batched or streamed into HDFS (or a landing zone). For relational data, Sqoop will import; for logs, Flume/Kafka provide streaming ingestion.
Key practices
- Use schema-on-read for flexibility — ingest raw data fast, interpret later.
- Timestamp and partition incoming data by date/hour to enable efficient queries.
2) Raw storage in HDFS
- Store original files as immutable objects in HDFS directories like
/data/raw/<source>/yyyy=.../. - Keep replication factor (default 3) for fault tolerance.
- Use appropriate block size (e.g., 128MB or 256MB) for large files.
Why raw storage matters: you can reprocess with new logic without losing original inputs.
3) Data processing / ETL
- Batch: MapReduce or Spark jobs transform raw files into curated datasets (parquet/ORC).
- Streaming / near real-time: Spark Streaming / Structured Streaming, Flink, Kafka Streams process data in micro-batches or event-by-event.
- Partition & format: convert to columnar formats (Parquet/ORC) and partition by date/customer/region.
Example PySpark ETL snippet (illustrative):
from pyspark.sql import SparkSession spark = SparkSession.builder.appName("etl").getOrCreate() raw = spark.read.json("hdfs:///data/raw/clicks/2025-11-19/*") clean = (raw .filter("event_type IS NOT NULL") .withColumn("event_ts", to_timestamp("ts")) .select("user_id","event_type","event_ts","properties")) # write to partitioned columnar format clean.write.mode("overwrite").partitionBy("event_date").parquet("hdfs:///data/curated/clicks/")
4) Indexing and fast access
- For low-latency reads you might put hot data into HBase, Druid, or a search index (Elasticsearch).
- Use Hive/Presto/Impala for interactive SQL queries over Parquet/ORC files.
5) Serving & analytics
- BI tools (Tableau, Power BI) connect to query layers (HiveServer2, Presto, Impala).
- Data scientists pull curated tables into notebooks for ML training (Spark MLlib, Python).
- Real-time use cases use model endpoints that read from Kafka or HBase.
6) Archival
- Move older data to cheaper tiers (cloud object store classes, HDFS archival nodes) while keeping metadata in the catalog.
C. How Hadoop components map to the pipeline
- Ingestion: Flume / Sqoop / Kafka feed data into HDFS.
- Storage: HDFS (primary). HBase for wide-column low-latency access.
- Compute: MapReduce for batch; Spark for faster batch, streaming, and ML.
- Resource Management: YARN schedules jobs, controls memory/CPU for each application.
- Processing Gateway: Hive (SQL), Pig (scripting), Spark (general compute).
- Streaming Coordination: Kafka + Spark Streaming or Flink for event-driven processing.
C. Integration with other Big Data technologies
Hadoop rarely works alone. Typical integrations:
- Kafka ⇄ HDFS / Spark: Kafka serves as buffering and stream transport; Spark consumes Kafka topics, processes events, writes results back to HDFS or HBase.
- Spark on YARN: deploy Spark applications using YARN for cluster resource management.
- Hive on Tez / Spark: Hive queries can run on faster execution engines (Tez or Spark) instead of MapReduce.
- Data Catalogs: Apache Atlas / Hive Metastore provide metadata and schema information for governance.
C. Real-world patterns & use cases (detailed)
Pattern: Batch analytics + daily reports
- Scenario: Retail chain needs nightly sales aggregation across 2,000 stores.
- Pipeline: POS systems -> Sqoop/Flume -> HDFS -> daily Spark job -> aggregated Parquet -> Hive table -> dashboards.
- Why Hadoop: stores huge raw logs and runs large joins and aggregations overnight.
Pattern: Near real-time fraud detection
- Scenario: Payment provider must flag suspicious transactions within seconds.
- Pipeline: Transaction stream -> Kafka -> Spark Structured Streaming with ML model -> flag writes to HBase / alerts -> human/automated action.
- Why Hadoop + Kafka + Spark: streaming + in-memory processing + persistent store for context.
Pattern: Personalization at scale
- Scenario: E-commerce site personalizes home pages for millions of users.
- Pipeline: Clickstream -> Kafka -> Spark streaming -> feature computation -> write features to HBase / Redis -> recommender service reads features for low-latency responses.
- Why Hadoop ecosystem: it provides the storage, processing, and serving layers needed for both batch model training and real-time feature serving.
Pattern: IoT telemetry analysis
- Scenario: Manufacturing plant monitors thousands of sensors.
- Pipeline: MQTT/Kafka -> time-series processing (Spark/Flink) -> windowed aggregations -> alerts and dashboards.
- Why Hadoop: long-term storage in HDFS + fast analytics with Spark.
D. Performance & scalability considerations
- Small files problem: HDFS is optimized for large files. Many small files (thousands of tiny files) cause high NameNode memory usage. Use sequence files or combine small files into larger containers.
- Block size tuning: Larger block sizes reduce metadata overhead for big files; 128MB or 256MB is common.
- Parallelism: Ensure jobs have enough tasks (partitions) to use the cluster fully—avoid skew where a few partitions are huge.
- Memory tuning: Spark executors and YARN containers need right-sizing (executor memory, cores) to balance throughput vs GC overhead.
- Shuffle optimization: Avoid excessive shuffles in Spark/MapReduce; use map-side aggregations when possible.
- Data locality: HDFS tries to run tasks where data lives; cluster rack-awareness improves fault tolerance but can affect locality.
E. Operational concerns: monitoring, security, governance
Monitoring & Observability
- Metrics to track: job success rates, latency (streaming), throughput (records/sec), NameNode/RM health, HDFS capacity and replication, GC stats, disk I/O.
- Tools: Ambari, Cloudera Manager, Grafana, Prometheus, ELK stack for logs.
- Alerts: node failure, slow tasks, disk nearing capacity, replication factor drift.
Security
- Authentication: Kerberos for strong authentication.
- Authorization: Ranger or Sentry to manage fine-grained access control.
- Encryption: TLS for transport, HDFS encryption zones for data at rest.
- Audit & Compliance: maintain audit logs, integrate with SIEM.
Data Governance
- Catalogs & lineage: Hive Metastore + Apache Atlas for metadata, lineage tracking.
- Quality checks: implement data validation jobs and SLAs.
- Pseudonymization & masking: sensitive fields in logs should be obfuscated during ingestion if needed.
F. Cost model and deployment options
On-prem vs Cloud vs Hybrid
- On-premises: full control, potentially cheaper at massive scale, but capital expense and ops burden are high.
- Cloud (EMR, Dataproc, HDInsight equivalents): easier provisioning, pay-as-you-go, managed clusters; often best for variable workloads.
- Hybrid: keep sensitive data on-prem, burst to cloud for heavy compute.
Cost levers
- Use spot/preemptible instances for non-critical jobs.
- Employ lifecycle policies to tier data (hot → warm → cold).
- Right-size clusters and autoscale when idle.
G. Best practices and patterns
- Ingest raw, immutable data and keep original copies.
- Convert to columnar formats (Parquet/ORC) for analytics.
- Partition data intelligently (by date, region).
- Keep schema changes backward-compatible or use schema evolution (Avro/Parquet).
- Use a metadata catalog and enforce SLAs.
- Separate compute and storage where possible (object stores + transient compute) for cost efficiency.
- Automate deployments and CI/CD for data jobs (version control Spark/Hive scripts).
- Test jobs on samples before running at scale.
- Monitor costs and implement alerts for runaway jobs.
H. Example end-to-end implementation summary (e-commerce)
- Goal: real-time personalization + nightly analytics
- Flow: Clicks → Kafka → Spark Structured Streaming (real-time features) → HBase/Redis for serving → daily Spark batch jobs on HDFS to compute aggregated KPIs → Hive tables for BI → nightly retraining of recommendation models with Spark MLlib → models written to model store and deployed to streaming pipeline.
- Why it works: HDFS stores durable historical data; Kafka and Spark handle real-time needs; HBase/Redis serve low-latency reads.
Expert Corner
- Hadoop provides the storage, resource management, and a powerful ecosystem. Big Data is the use case — the mountain Hadoop helps you climb.
- Real systems combine batch and streaming, curated and raw layers, and multiple serving technologies.
- Good architecture balances scalability, cost, latency, and governance — and the Hadoop ecosystem gives you building blocks to do that.
